📖 Sommaire
- 1. C’est quoi la donnée synthétique ? (Et pourquoi on en a besoin)
- 2. Les limites des anciennes méthodes
- 3. Entrez dans l’arène : Voici Simula !
- 4. Pourquoi Simula change la donne ?
- Conclusion
Comprendre Simula : La révolution des données synthétiques par l’IA
Vous entendez souvent parler d’Intelligence Artificielle (IA) et de modèles toujours plus performants. Mais savez-vous quel est le carburant principal de ces IA ? Les données. Aujourd’hui, nous faisons face à un défi majeur : nous manquons de données spécifiques et de qualité pour entraîner des IA ultra-spécialisées. C’est ici qu’intervient une solution fascinante : les données synthétiques et un nouvel outil révolutionnaire de Google appelé Simula.
Dans cet article très complet, nous allons reprendre tout depuis le début. Que vous soyez novice ou curieux, attachez votre ceinture : nous partons explorer l’avenir de l’apprentissage automatique !
1. C’est quoi la donnée synthétique ? (Et pourquoi on en a besoin)
Le problème du “Monde Réel”
Imaginez que vous vouliez apprendre à une IA à reconnaître un “chat rouge” dans n’importe quelle situation. Si vous utilisez des données du monde réel (des photos prises par des humains), vous allez rencontrer trois gros problèmes :
- La rareté : Trouver des milliers de photos de “chats rouges” (un pelage très spécifique ou teinté) est extrêmement difficile.
- Le coût et le temps : Demander à des humains de trier et d’étiqueter ces photos coûte très cher et prend un temps fou.
- Le manque de contrôle : Dans vos photos réelles, le chat pourrait toujours être caché dans l’ombre, ou toujours sur un canapé, ce qui biaise l’apprentissage de l’IA.
La solution : Fabriquer nos propres données
Les données synthétiques sont des données qui ne sont pas collectées dans le monde réel, mais générées artificiellement par des ordinateurs. Au lieu de chercher des photos de chats rouges, nous demandons à un programme de dessiner des millions de chats rouges dans toutes les situations imaginables (au soleil, sous la pluie, à moitié caché, etc.).
Une “bonne” donnée synthétique doit respecter trois règles d’or :
- La Qualité : Est-ce que l’image montre bien un chat, et est-il vraiment rouge ?
- La Complexité : Est-ce que l’image est un défi pour l’IA ? (ex: un chat rouge caché derrière une plante).
- La Diversité : Avons-nous assez de races de chats différentes, de poses, et de décors ?
2. Les limites des anciennes méthodes
Jusqu’à présent, pour créer des données synthétiques, les humains devaient écrire manuellement de longues instructions (des “prompts”) ou fournir des exemples de départ (des “graines” ou seeds).
Le problème ? C’est très lent, cela demande beaucoup d’efforts humains, et surtout, on reste limité par l’imagination humaine. Si un humain oublie de demander un chat rouge “sous la neige”, l’IA ne verra jamais ce cas de figure. Il nous fallait donc une méthode capable de réfléchir et de s’étendre toute seule.
3. Entrez dans l’arène : Voici Simula !
Publié récemment par Google Research, Simula est un nouveau système (framework) intelligent conçu pour générer et évaluer des données synthétiques à une échelle massive, sans avoir besoin d’exemples humains au départ.
Simula fonctionne avec ce qu’on appelle une approche “Agentique” (il agit comme un agent autonome) et est guidé par le “Raisonnement”.
Comment fonctionne Simula ? Le processus en bref
Plutôt que de générer des données au hasard, Simula “réfléchit” et organise ses idées. Il construit ce qu’on appelle une Taxonomie (un arbre de classification très détaillé) pour s’assurer de couvrir absolument tous les sujets possibles.
Voici un schéma simple pour comprendre la boucle de réflexion de Simula (la méthode “Proposer et Affiner”) :
graph TD
A[Début : Domaine Cible<br>ex: Cybersécurité] --> B[Agent Proposeur<br>Génère des sous-catégories]
B --> C{Agent Critique<br>Évalue les propositions}
C -- Invalide / Doublon --> B
C -- Valide --> D[Ajout à l'Arbre de Taxonomie]
D --> E{Taxonomie assez grande ?}
E -- Non --> B
E -- Oui --> F[Génération des Données Synthétiques Finales]
style A fill:#4285F4,stroke:#333,stroke-width:2px,color:white
style B fill:#34A853,stroke:#333,stroke-width:2px,color:white
style C fill:#FBBC05,stroke:#333,stroke-width:2px,color:black
style D fill:#EA4335,stroke:#333,stroke-width:2px,color:white
style F fill:#9C27B0,stroke:#333,stroke-width:2px,color:whiteExplication de la boucle “Propose-and-Refine” :
- L’Agent Proposeur : À partir d’un sujet (ex: Les menaces informatiques), une IA propose des idées de sous-sujets.
- L’Agent Critique : Une deuxième IA agit comme un juge. Elle regarde les propositions et dit : “Attends, tu as déjà proposé ça” ou “Ce n’est pas logique”. Elle filtre et fusionne les idées.
- L’Expansion Récursive : Une fois validées, ces idées deviennent les branches d’un arbre gigantesque. Le système recommence pour chaque nouvelle branche, créant des feuilles de plus en plus précises.
Grâce à cette méthode, Simula garantit une diversité globale incroyable sans aucune intervention humaine !
4. Pourquoi Simula change la donne ?
Des résultats impressionnants
Pour prouver l’efficacité de Simula, les chercheurs l’ont testé sur des tâches très complexes. Les résultats montrent que les modèles entraînés avec les données de Simula surpassent largement les anciennes méthodes.
Voici le graphique officiel des résultats publiés par l’équipe de recherche :
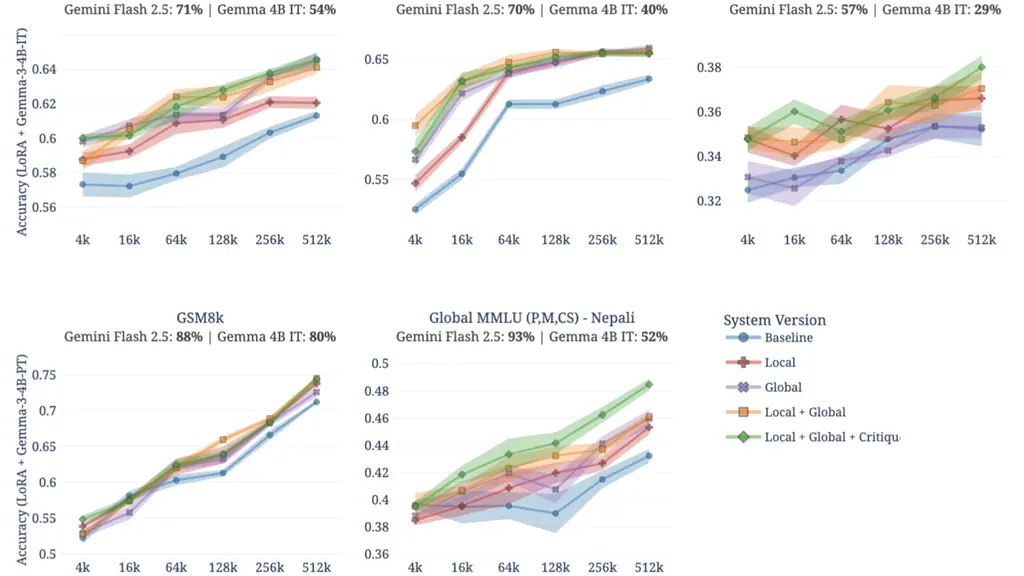 Légende : Ce graphique illustre les performances des modèles entraînés avec les données générées par Simula comparées aux autres méthodes.
Légende : Ce graphique illustre les performances des modèles entraînés avec les données générées par Simula comparées aux autres méthodes.
Les trois grands avantages de Simula :
- Scalabilité (Mise à l’échelle) : Comme il n’a pas besoin de “graines” humaines, Simula peut générer des milliards de données sans se fatiguer.
- Explicabilité : Parce qu’il construit un arbre de décision clair, les chercheurs peuvent auditer et comprendre exactement comment chaque donnée a été inventée. C’est crucial pour des domaines sensibles comme la médecine ou la sécurité.
- Contrôle précis : Les créateurs peuvent dire à Simula : “Concentre 80% de ton énergie à générer des données très difficiles, et 20% sur des données faciles”. C’est ce qu’on appelle l’allocation fine des ressources.
pie title Répartition de l'effort contrôlé par Simula (Exemple)
"Données Très Complexes (80%)" : 80
"Données Faciles de Base (20%)" : 20Conclusion
La création de données synthétiques n’est plus seulement une astuce pour gagner du temps : c’est le futur du développement des Intelligences Artificielles. Avec des frameworks raisonnés et autonomes comme Simula, nous sommes capables de surmonter les obstacles liés à la rareté des données, au respect de la vie privée et aux coûts astronomiques.
En remplaçant les processus manuels fastidieux par une conception mécanique intelligente (Mechanism Design), Google Research nous montre la voie vers des IA plus sûres, plus spécialisées et beaucoup plus performantes.
L’avenir ne s’apprend pas seulement en observant le passé, il se simule.
Ressources :
Voici quelques autres illustrations tirées des recherches de Google :
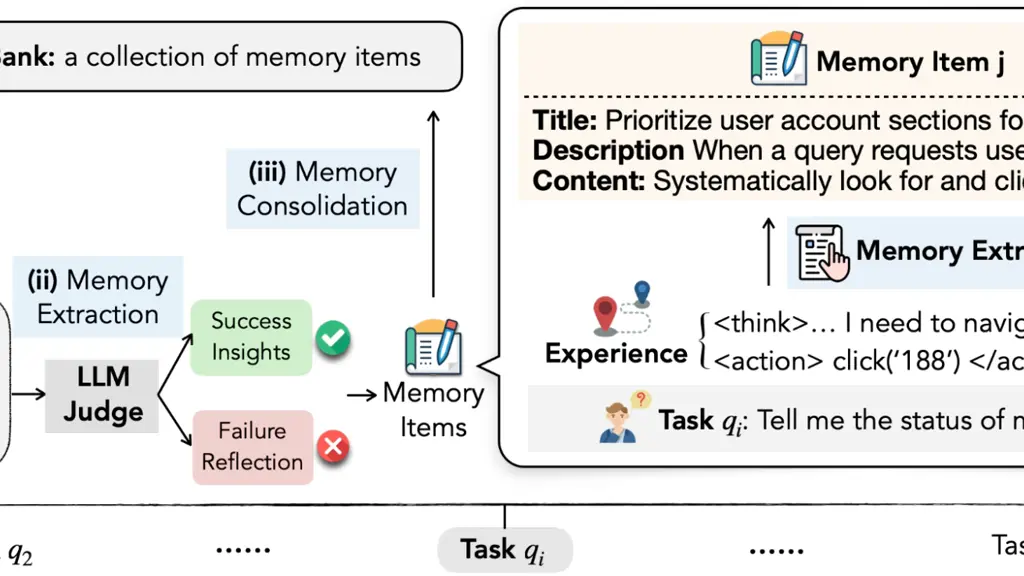 Exemple d’une “Banque de Raisonnement” utilisée par le système pour vérifier la logique des données générées.
Exemple d’une “Banque de Raisonnement” utilisée par le système pour vérifier la logique des données générées.
